Pose Estimation Models Export
This tutorial shows how to export YoloNAS-Pose model to ONNX format for deployment to ONNX-compatible runtimes and accelerators.
From this tutorial you will learn:
- How to export YoloNAS-Pose model to ONNX and run it with ONNXRuntime / TensorRT
- How to enable FP16 / INT8 quantization and export a model with calibration
- How to customize NMS parameters and number of detections per image
- How to choose whether to use TensorRT or ONNXRuntime as a backend
Supported pose estimation models
- YoloNAS-Pose N,S,M,L
Supported features
- Exporting a model to OnnxRuntime and TensorRT
- Exporting a model with preprocessing (e.g. normalizing/standardizing image according to normalization parameters during training)
- Exporting a model with postprocessing (e.g. predictions decoding and NMS) - you obtain the ready-to-consume bounding box outputs
- FP16 / INT8 quantization support with calibration
- Pre- and post-processing steps can be customized by the user if needed
- Customising input image shape and batch size
- Customising NMS parameters and number of detections per image
- Customising output format (flat or batched)
Support matrix
It is important to note that different versions of TensorRT has varying support of ONNX opsets. The support matrix below shows the compatibility of different versions of TensorRT runtime in regard to batch size and output format. We recommend to use the latest version of TensorRT available.
| Batch Size | Format | OnnxRuntime 1.13.1 | TensorRT 8.4.2 | TensorRT 8.5.3 | TensorRT 8.6.1 |
|---|---|---|---|---|---|
| 1 | Flat | Yes | Yes | Yes | Yes |
| >1 | Flat | Yes | Yes | Yes | Yes |
| 1 | Batch | Yes | No | No | Yes |
| >1 | Batch | Yes | No | No | Yes |
!pip install -qq super-gradients==3.4.0
Minimalistic export example
Let start with the most simple example of exporting a model to ONNX format.
We will use YoloNAS-S model in this example. All models that suports new export API now expose a export() method that can be used to export a model. There is one mandatory argument that should be passed to the export() method - the path to the output file. Currently, only .onnx format is supported, but we may add support for CoreML and other formats in the future.
from super_gradients.common.object_names import Models
from super_gradients.training import models
model = models.get(Models.YOLO_NAS_POSE_S, pretrained_weights="coco_pose")
export_result = model.export("yolo_nas_pose_s.onnx")
A lot of work just happened under the hood:
- A model was exported to ONNX format using default batch size of 1 and input image shape that was used during training
- A preprocessing and postprocessing steps were attached to ONNX graph
- For pre-processing step, the normalization parameters were extracted from the model itself (to be consistent with the image normalization and channel order used during training)
- For post-processing step, the NMS parameters were also extracted from the model and NMS module was attached to the graph
- ONNX graph was checked and simplified to improve compatibility with ONNX runtimes.
A returned value of export() method is an instance of ModelExportResult class.
First of all it serves the purpose of storing all the information about the exported model in a single place.
It also provides a convenient way to get an example of running the model and getting the output:
export_result
Model exported successfully to yolo_nas_pose_s.onnx
Model expects input image of shape [1, 3, 640, 640]
Input image dtype is torch.uint8
Exported model already contains preprocessing (normalization) step, so you don't need to do it manually.
Preprocessing steps to be applied to input image are:
Sequential(
(0): CastTensorTo(dtype=torch.float32)
(1): ChannelSelect(channels_indexes=tensor([2, 1, 0]))
(2): ApplyMeanStd(mean=[0.], scale=[255.])
)
Exported model contains postprocessing (NMS) step with the following parameters:
num_pre_nms_predictions=1000
max_predictions_per_image=1000
nms_threshold=0.7
confidence_threshold=0.05
output_predictions_format=batch
Exported model is in ONNX format and can be used with ONNXRuntime
To run inference with ONNXRuntime, please use the following code snippet:
import onnxruntime
import numpy as np
session = onnxruntime.InferenceSession("yolo_nas_pose_s.onnx", providers=["CUDAExecutionProvider", "CPUExecutionProvider"])
inputs = [o.name for o in session.get_inputs()]
outputs = [o.name for o in session.get_outputs()]
example_input_image = np.zeros((1, 3, 640, 640)).astype(np.uint8)
predictions = session.run(outputs, {inputs[0]: example_input_image})
Exported model can also be used with TensorRT
To run inference with TensorRT, please see TensorRT deployment documentation
You can benchmark the model using the following code snippet:
trtexec --onnx=yolo_nas_pose_s.onnx --fp16 --avgRuns=100 --duration=15
Exported model has predictions in batch format:
num_detections, pred_boxes, pred_scores, pred_joints = predictions
for image_index in range(num_detections.shape[0]):
for i in range(num_detections[image_index,0]):
confidence = pred_scores[image_index, i]
x_min, y_min, x_max, y_max = pred_boxes[image_index, i]
pred_joints = pred_joints[image_index, i]
print(f"Detected pose with confidence={confidence}, x_min={x_min}, y_min={y_min}, x_max={x_max}, y_max={y_max}")
for joint_index, (x, y, confidence) in enumerate(pred_joints[i]):
print(f"Joint {joint_index} has coordinates x={x}, y={y}, confidence={confidence}")
That's it. You can now use the exported model with any ONNX-compatible runtime or accelerator.
import cv2
import numpy as np
from super_gradients.training.utils.media.image import load_image
import onnxruntime
image = load_image("https://deci-pretrained-models.s3.amazonaws.com/sample_images/beatles-abbeyroad.jpg")
image = cv2.resize(image, (export_result.input_image_shape[1], export_result.input_image_shape[0]))
image_bchw = np.transpose(np.expand_dims(image, 0), (0, 3, 1, 2))
session = onnxruntime.InferenceSession(export_result.output,
providers=["CUDAExecutionProvider", "CPUExecutionProvider"])
inputs = [o.name for o in session.get_inputs()]
outputs = [o.name for o in session.get_outputs()]
result = session.run(outputs, {inputs[0]: image_bchw})
result[0].shape, result[1].shape, result[2].shape, result[3].shape
((1, 1), (1, 1000, 4), (1, 1000), (1, 1000, 17, 3))
In the next section we unpack the result of prediction and show how to use it.
Output format for detection models
If preprocessing=True (default value) then all models will be exported with NMS. If preprocessing=False models will be exported without NMS and raw model outputs will be returned. In this case, you will need to apply NMS yourself. This is useful if you want to use a custom NMS implementation that is not ONNX-compatible. In most cases you will want to use default preprocessing=True. It is also possible to pass a custom nn.Module as a postprocessing argument to the export() method. This module will be attached to the exported ONNX graph instead of the default NMS module. We encourage users to read the documentation of the export() method to learn more about the advanced options.
When exporting an object detection model with postprocessing enabled, the prediction format can be one of two:
- A "flat" format -
DetectionOutputFormatMode.FLAT_FORMAT - A "batched" format -
DetectionOutputFormatMode.BATCH_FORMAT
You can select the desired output format by setting export(..., output_predictions_format=DetectionOutputFormatMode.BATCH_FORMAT).
Flat format
A detection results returned as a single tensor of shape [N, 6 + 3 * NumKeypoints], where N is the number of detected objects in the entire batch. Each row in the tensor represents a single detection result and has the following format:
[batch_index, x1, y1, x2, y2, pose confidence, (x,y,score) * num_keypoints]
When exporting a model with batch size of 1 (default mode) you can ignore the first column as all boxes will belong to the single sample. In case you export model with batch size > 1 you have to iterate over this array like so:
def iterate_over_flat_predictions(predictions, batch_size):
[flat_predictions] = predictions
for image_index in range(batch_size):
mask = flat_predictions[:, 0] == image_index
pred_bboxes = flat_predictions[mask, 1:5]
pred_scores = flat_predictions[mask, 5]
pred_joints = flat_predictions[mask, 6:].reshape((len(pred_bboxes), -1, 3))
yield image_index, pred_bboxes, pred_scores, pred_joints
Iteration over the predictions would be as follows:
for image_index, pred_bboxes, pred_scores, pred_joints in iterate_over_flat_predictions(predictions, batch_size):
... # Do something useful with the predictions
Batch format
A second supported format is so-called "batch". It matches with output format of TensorRT's NMS implementation. The return value in this case is tuple of 4 tensors:
num_predictions- [B, 1] - A number of predictions per samplepred_boxes- [B, N, 4] - A coordinates of the predicted boxes in X1, Y1, X2, Y2 formatpred_scores- [B, N] - A scores of the predicted boxespred_classes- [B, N] - A class indices of the predicted boxes
Here B corresponds to batch size and N is the maximum number of detected objects per image.
In order to get the actual number of detections per image you need to iterate over num_predictions tensor and get the first element of each row.
A corresponding code snippet for iterating over the batch predictions would look like this:
def iterate_over_batch_predictions(predictions, batch_size):
num_detections, batch_boxes, batch_scores, batch_joints = predictions
for image_index in range(batch_size):
num_detection_in_image = num_detections[image_index, 0]
pred_scores = batch_scores[image_index, :num_detection_in_image]
pred_boxes = batch_boxes[image_index, :num_detection_in_image]
pred_joints = batch_joints[image_index, :num_detection_in_image].reshape((len(pred_scores), -1, 3))
yield image_index, pred_boxes, pred_scores, pred_joints
And similary to flat format, iteration over the predictions would be as follows:
for image_index, pred_bboxes, pred_scores, pred_joints in iterate_over_batch_predictions(predictions, batch_size):
... # Do something useful with the predictions
Now when you're familiar with the output formats, let's see how to use them. To start, it's useful to take a look at the values of the predictions with a naked eye:
num_predictions, pred_boxes, pred_scores, pred_poses = result
num_predictions
array([[9]], dtype=int64)
np.set_printoptions(threshold=3, edgeitems=3)
pred_boxes, pred_boxes.shape
(array([[[182.49644 , 249.07802 , 305.27576 , 530.3644 ],
[ 34.52883 , 247.74242 , 175.7783 , 544.1926 ],
[438.808 , 251.08049 , 587.11865 , 552.69336 ],
...,
[ 67.20265 , 248.3974 , 122.415375, 371.65637 ],
[625.7083 , 306.74194 , 639.4926 , 501.08337 ],
[450.61108 , 386.74622 , 556.77325 , 523.2412 ]]], dtype=float32),
(1, 1000, 4))
np.set_printoptions(threshold=3, edgeitems=3)
pred_scores, pred_scores.shape
(array([[0.84752125, 0.826281 , 0.82436883, ..., 0.00848398, 0.00848269,
0.00848123]], dtype=float32),
(1, 1000))
np.set_printoptions(threshold=3, edgeitems=3)
pred_poses, pred_poses.shape
(array([[[[2.62617737e+02, 2.75986389e+02, 7.74692297e-01],
[2.63401123e+02, 2.70397522e+02, 3.57395113e-01],
[2.57980499e+02, 2.70888336e+02, 7.75521040e-01],
...,
[2.58518188e+02, 4.50223969e+02, 9.40084636e-01],
[2.01152466e+02, 5.02089630e+02, 8.42420936e-01],
[2.82095978e+02, 5.06688324e+02, 8.73963714e-01]],
[[1.14750252e+02, 2.75872864e+02, 8.29551518e-01],
[1.15829544e+02, 2.70712891e+02, 4.48927283e-01],
[1.09389343e+02, 2.70643494e+02, 8.33203077e-01],
...,
[7.29626541e+01, 4.55435028e+02, 9.07496691e-01],
[1.47440369e+02, 5.05209564e+02, 8.53177905e-01],
[5.24395561e+01, 5.16123291e+02, 8.44702840e-01]],
[[5.46199341e+02, 2.83605713e+02, 6.09813333e-01],
[5.45253479e+02, 2.78786011e+02, 1.59033239e-01],
[5.44112183e+02, 2.78675476e+02, 5.77503145e-01],
...,
[5.00366119e+02, 4.57584869e+02, 8.84028912e-01],
[5.50320129e+02, 5.21863281e+02, 7.15586364e-01],
[4.54590271e+02, 5.17590332e+02, 7.93488443e-01]],
...,
[[1.13875908e+02, 2.76212708e+02, 7.35527277e-01],
[1.16164986e+02, 2.70696411e+02, 4.00955290e-01],
[1.08107491e+02, 2.70656555e+02, 7.91907310e-01],
...,
[9.75953293e+01, 4.07489868e+02, 3.45197320e-01],
[1.01579475e+02, 4.40818176e+02, 2.17337132e-01],
[9.04172211e+01, 4.44152771e+02, 2.28111655e-01]],
[[6.42500244e+02, 3.39081055e+02, 1.75797671e-01],
[6.42386841e+02, 3.34906342e+02, 1.55016124e-01],
[6.41675354e+02, 3.34820374e+02, 1.29657656e-01],
...,
[6.40000122e+02, 4.15383392e+02, 2.22081602e-01],
[6.37456421e+02, 4.40941406e+02, 2.00318485e-01],
[6.39243164e+02, 4.41459686e+02, 2.33620048e-01]],
[[5.17478271e+02, 4.09209961e+02, 1.95783913e-01],
[5.21710632e+02, 4.01950928e+02, 1.90346301e-01],
[5.12909302e+02, 4.02274841e+02, 1.88751698e-01],
...,
[4.98697205e+02, 4.55512695e+02, 4.54110742e-01],
[5.19384705e+02, 5.21536316e+02, 4.20579553e-01],
[4.83649933e+02, 5.19510498e+02, 4.25356269e-01]]]],
dtype=float32),
(1, 1000, 17, 3))
Visualizing predictions
For sake of this tutorial we will use a simple visualization function that is tailored for batch_size=1 only. You can use it as a starting point for your own visualization code.
from super_gradients.training.utils.visualization.pose_estimation import PoseVisualization
import matplotlib.pyplot as plt
def show_predictions_from_batch_format(image, predictions):
# In this tutorial we are using batch size of 1, therefore we are getting only first element of the predictions
image_index, pred_boxes, pred_scores, pred_joints = next(iter(iterate_over_batch_predictions(predictions, 1)))
image = PoseVisualization.draw_poses(
image=image, poses=pred_joints, scores=pred_scores, boxes=pred_boxes,
edge_links=None, edge_colors=None, keypoint_colors=None, is_crowd=None
)
plt.figure(figsize=(8, 8))
plt.imshow(image)
plt.tight_layout()
plt.show()
show_predictions_from_batch_format(image, result)
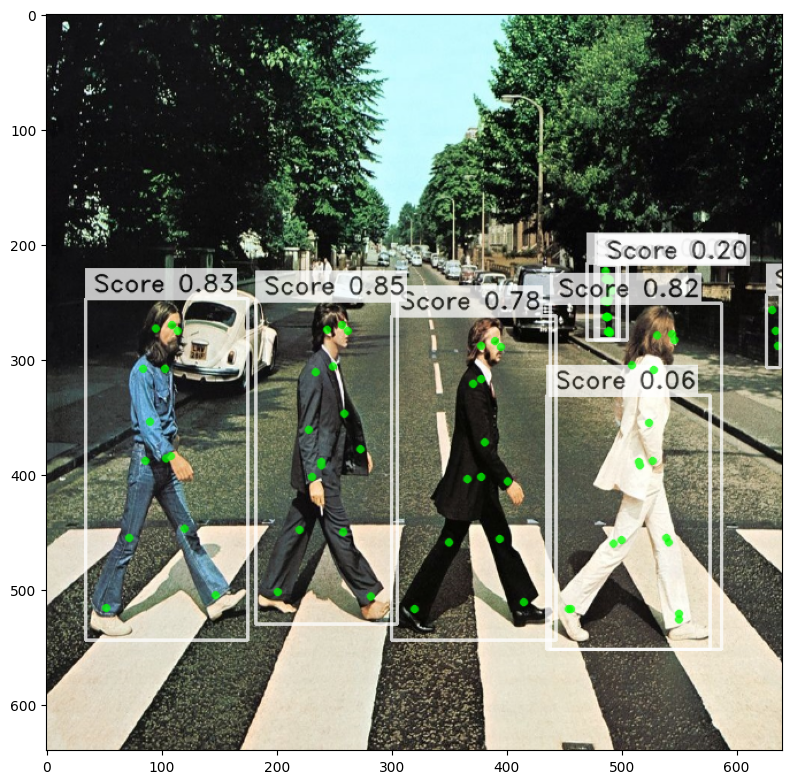
Changing the output format
You can explicitly specify output format of the predictions by setting the output_predictions_format argument of export() method. Let's see how it works:
from super_gradients.conversion import DetectionOutputFormatMode
export_result = model.export("yolo_nas_s.onnx", output_predictions_format=DetectionOutputFormatMode.FLAT_FORMAT)
export_result
Model exported successfully to yolo_nas_s.onnx
Model expects input image of shape [1, 3, 640, 640]
Input image dtype is torch.uint8
Exported model already contains preprocessing (normalization) step, so you don't need to do it manually.
Preprocessing steps to be applied to input image are:
Sequential(
(0): CastTensorTo(dtype=torch.float32)
(1): ChannelSelect(channels_indexes=tensor([2, 1, 0]))
(2): ApplyMeanStd(mean=[0.], scale=[255.])
)
Exported model contains postprocessing (NMS) step with the following parameters:
num_pre_nms_predictions=1000
max_predictions_per_image=1000
nms_threshold=0.7
confidence_threshold=0.05
output_predictions_format=flat
Exported model is in ONNX format and can be used with ONNXRuntime
To run inference with ONNXRuntime, please use the following code snippet:
import onnxruntime
import numpy as np
session = onnxruntime.InferenceSession("yolo_nas_s.onnx", providers=["CUDAExecutionProvider", "CPUExecutionProvider"])
inputs = [o.name for o in session.get_inputs()]
outputs = [o.name for o in session.get_outputs()]
example_input_image = np.zeros((1, 3, 640, 640)).astype(np.uint8)
predictions = session.run(outputs, {inputs[0]: example_input_image})
Exported model can also be used with TensorRT
To run inference with TensorRT, please see TensorRT deployment documentation
You can benchmark the model using the following code snippet:
trtexec --onnx=yolo_nas_s.onnx --fp16 --avgRuns=100 --duration=15
Exported model has predictions in flat format:
# flat_predictions is a 2D array of [N,K] shape
# Each row represents (image_index, x_min, y_min, x_max, y_max, confidence, joints...)
# Please note all values are floats, so you have to convert them to integers if needed
[flat_predictions] = predictions
pred_bboxes = flat_predictions[:, 1:5]
pred_scores = flat_predictions[:, 5]
pred_joints = flat_predictions[:, 6:].reshape((len(pred_bboxes), -1, 3))
for i in range(len(pred_bboxes)):
confidence = pred_scores[i]
x_min, y_min, x_max, y_max = pred_bboxes[i]
print(f"Detected pose with confidence={{confidence}}, x_min={{x_min}}, y_min={{y_min}}, x_max={{x_max}}, y_max={{y_max}}")
for joint_index, (x, y, confidence) in enumerate(pred_joints[i]):")
print(f"Joint {{joint_index}} has coordinates x={{x}}, y={{y}}, confidence={{confidence}}")
Now we exported a model that produces predictions in flat format. Let's run the model like before and see the result:
session = onnxruntime.InferenceSession(export_result.output,
providers=["CUDAExecutionProvider", "CPUExecutionProvider"])
inputs = [o.name for o in session.get_inputs()]
outputs = [o.name for o in session.get_outputs()]
result = session.run(outputs, {inputs[0]: image_bchw})
result[0].shape
(9, 57)
def show_predictions_from_flat_format(image, predictions):
image_index, pred_boxes, pred_scores, pred_joints = next(iter(iterate_over_flat_predictions(predictions, 1)))
image = PoseVisualization.draw_poses(
image=image, poses=pred_joints, scores=pred_scores, boxes=pred_boxes,
edge_links=None, edge_colors=None, keypoint_colors=None, is_crowd=None
)
plt.figure(figsize=(8, 8))
plt.imshow(image)
plt.tight_layout()
plt.show()
show_predictions_from_flat_format(image, result)
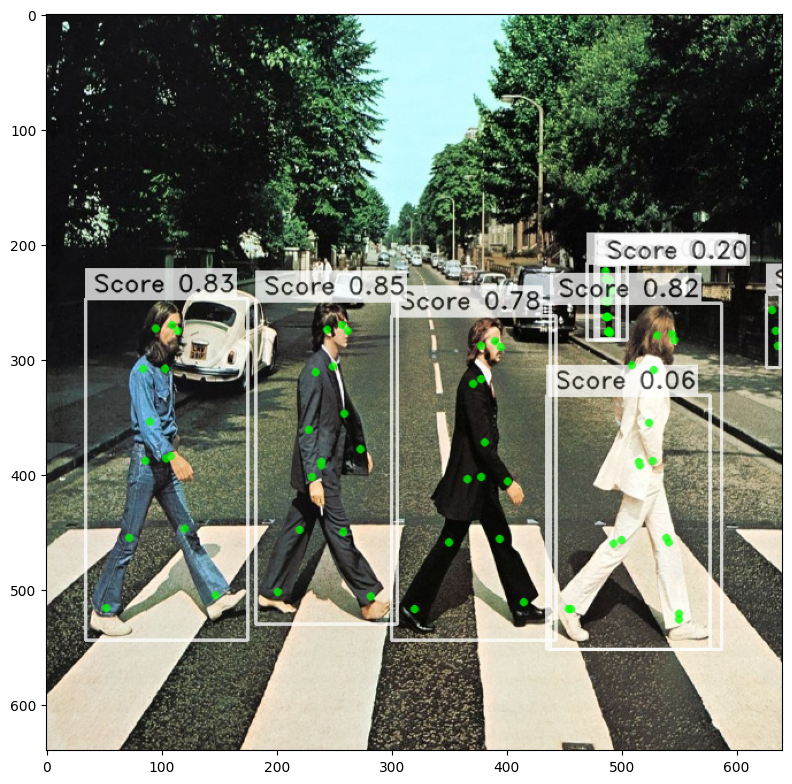
Changing postprocessing settings
You can control a number of parameters in the NMS settings as well as maximum number of detections per image before and after NMS step:
- IOU threshold for NMS -
nms_iou_threshold - Score threshold for NMS -
nms_score_threshold - Maximum number of detections per image before NMS -
max_detections_before_nms - Maximum number of detections per image after NMS -
max_detections_after_nms
For sake of demonstration, let's export a model that would produce at most one detection per image with confidence threshold above 0.8 and NMS IOU threshold of 0.5. Let's use at most 100 predictions per image before NMS step:
export_result = model.export(
"yolo_nas_s_pose_top_1.onnx",
confidence_threshold=0.8,
nms_threshold=0.5,
num_pre_nms_predictions=100,
max_predictions_per_image=1,
output_predictions_format=DetectionOutputFormatMode.FLAT_FORMAT
)
session = onnxruntime.InferenceSession(export_result.output,
providers=["CUDAExecutionProvider", "CPUExecutionProvider"])
inputs = [o.name for o in session.get_inputs()]
outputs = [o.name for o in session.get_outputs()]
result = session.run(outputs, {inputs[0]: image_bchw})
show_predictions_from_flat_format(image, result)

As expected, the predictions contains exactly one detection with the highest confidence score.
Export of quantized model
You can export a model with quantization to FP16 or INT8. To do so, you need to specify the quantization_mode argument of export() method.
Important notes: * Quantization to FP16 requires CUDA / MPS device available and would not work on CPU-only machines.
Let's see how it works:
from super_gradients.conversion.conversion_enums import ExportQuantizationMode
export_result = model.export(
"yolo_nas_pose_s_int8.onnx",
confidence_threshold=0.5,
output_predictions_format=DetectionOutputFormatMode.FLAT_FORMAT,
quantization_mode=ExportQuantizationMode.INT8 # or ExportQuantizationMode.FP16
)
session = onnxruntime.InferenceSession(export_result.output,
providers=["CUDAExecutionProvider", "CPUExecutionProvider"])
inputs = [o.name for o in session.get_inputs()]
outputs = [o.name for o in session.get_outputs()]
result = session.run(outputs, {inputs[0]: image_bchw})
show_predictions_from_flat_format(image, result)

Advanced INT-8 quantization options
When quantizing a model using quantization_mode==ExportQuantizationMode.INT8 you can pass a DataLoader to export() function to collect correct statistics of activations to prodice a more accurate quantized model.
We expect the DataLoader to return either a tuple of tensors or a single tensor. In case a tuple of tensors is returned by data-loader the first element will be used as input image.
You can use existing data-loaders from SG here as is.
Important notes
* A calibration_loader should use same image normalization parameters that were used during training.
In the example below we use a dummy data-loader for sake of showing how to use this feature. You should use your own data-loader here.
import torch
from torch.utils.data import DataLoader
from super_gradients.conversion import ExportQuantizationMode
# THIS IS ONLY AN EXAMPLE. YOU SHOULD USE YOUR OWN DATA-LOADER HERE
dummy_calibration_dataset = [torch.randn((3, 640, 640), dtype=torch.float32) for _ in range(32)]
dummy_calibration_loader = DataLoader(dummy_calibration_dataset, batch_size=8, num_workers=0)
# THIS IS ONLY AN EXAMPLE. YOU SHOULD USE YOUR OWN DATA-LOADER HERE
export_result = model.export(
"yolo_nas_pose_s_int8_with_calibration.onnx",
confidence_threshold=0.5,
output_predictions_format=DetectionOutputFormatMode.FLAT_FORMAT,
quantization_mode=ExportQuantizationMode.INT8,
calibration_loader=dummy_calibration_loader
)
session = onnxruntime.InferenceSession(export_result.output,
providers=["CUDAExecutionProvider", "CPUExecutionProvider"])
inputs = [o.name for o in session.get_inputs()]
outputs = [o.name for o in session.get_outputs()]
result = session.run(outputs, {inputs[0]: image_bchw})
show_predictions_from_flat_format(image, result)
25%|█████████████████████████████████ | 4/16 [00:12<00:37, 3.10s/it]

Limitations
- Dynamic batch size / input image shape is not supported yet. You can only export a model with a fixed batch size and input image shape.
- TensorRT of version 8.5.2 or higher is required.
- Quantization to FP16 requires CUDA / MPS device available.
Conclusion
This concludes the export tutorial for YoloNAS-Pose pose estimation model. We hope you found it useful and will be able to use it to export your own models to ONNX format.
In case you have any questions or issues, please feel free to reach out to us at https://github.com/Deci-AI/super-gradients/issues.