Model Optimization Quickstart
Prerequisite - Client Setup
Make sure to have configured your environment as per Installation & Setup.
Overview
In this tutorial we are going to explore the basic capabilities of the platform client. This includes the basic operations of installing the client, generating and configuring an access token for using the platform client. Then, we are going to have a walkthrough example of:
- Registering an ONNX model to the platform
- Performing optimization of this model
- Downloading the optimized model
- Access the benchmark results of the optimized model
1. Register your model to the platform
Register your model to the platform
The platform support multiple frameworks:
- ONNX, TensorFlow2 and Keras models - These models can be registered to the platform from local file or from public S3.
- PyTorch models - These models can be registered to the platform from local loaded model only. Please see the PyTorch and Hugging Face Models Tutorial.
The following section will register an ONNX model to the platform from local file.
>>> from deci_platform_client.models import FrameworkType
>>> model_id = client.register_model(model="/path/to/model.onnx", name="My First Model", framework=FrameworkType.ONNX)
deci_platform_client -INFO- Uploading the model file...
deci_platform_client -INFO- Finished uploading the model file.
The model will be registered and uploaded to the platform with the name "My First Model" and framework ONNX.
For more information about the register_model method and parameters, with usage examples, refer to the code reference.
2. Optimize Your Model
Optimize your model
The platform uses Infery to optimize and benchmark your model.
The optimization process consist of compilation process to a target framework. The frameworks that are currently supported in the platform are:
- NVIDIA TensorRT for NVIDIA GPUs
- Intel OpenVINO for Intel CPUs
In order to optimize the previously registered model to NVIDIA T4 GPU, you will need to run the following line of code:
>>> from deci_platform_client.models import HardwareType
>>> optimized_model_ids = client.optimize_model(model_id=model_id, hardware_types=[HardwareType.T4])
This will trigger optimization job on the model to optimize it to the specified hardware for batch size 1 and quantization level FP16.
You can set those parameters to other values, as specified in the optimize_model method documentation.
The optimization process can take a while (up to 1 hour), and you will get an email from the platform upon successful optimization of your model. If you wish to track the progress of your optimization process you can use the Lab tab in the platform.
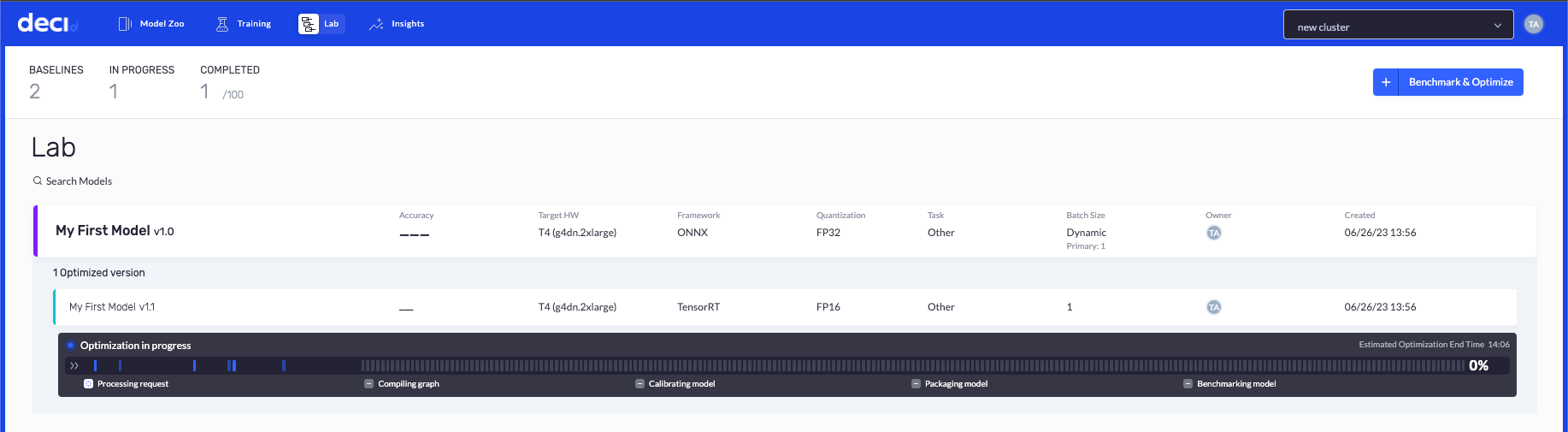
3. Get your optimized model
Get your optimized model
Once the optimization process has completed successfully, you can get the optimized model as well as the benchmark results using the get_model method:
>>> model_metadata, model_path = client.get_model(name="My First Model", version="1.1")
deci_platform_client -INFO- Downloading...
/Users/talorabramovich/My First Model_1_1.pkl: | | 22.5M/? [00:09<00:00, 2.53MB/s]
deci_platform_client -INFO- The model was downloaded to /Users/talorabramovich/My First Model_1_1.pkl
>>> model_metadata["benchmark"][HardwareType.T4][-1]["batchInfTime"]
Decimal('0.84351518965645488901117232671822421252727508544921875')
The model was downloaded to the current working directory, and you can also access the benchmark results on the hardware type you optimized the model for. For more information about the benchmark results parameter refer to Infery documentation.
For more information about the get_model method and parameters refer to code reference.
Summary
In this tutorial, you've accomplished the following tasks using the platform SDK:
- Access Token Generation and Login: You successfully generated an access token and logged into the platform, gaining access to its features and functionalities.
- Model Registration: You registered your first model on the platform, allowing you to utilize it for various tasks and applications.
- Optimization Request: You submitted a optimization request, indicating your desired configurations and specifications for the model.
- Optimized Model for NVIDIA T4 GPU: As a result of your optimization request, you obtained your first optimized model optimized for the NVIDIA T4 GPU, ensuring efficient and effective performance.
Full Example
# Importing libraries
from deci_platform_client import DeciPlatformClient
from deci_platform_client.models import FrameworkType, HardwareType
# Login using the client
client = DeciPlatformClient()
# Register a model, send an optimization request and retrieve the optimized model
model_id = client.register_model(model="/path/to/model.onnx", name="My First Model", framework=FrameworkType.ONNX)
optimized_model_ids = client.optimize_model(model_id=model_id, hardware_types=[HardwareType.T4])
model_metadata, model_path = client.get_model(name="My First Model", version="1.1")
print(f"Model path: {model_path}. Inference time on {HardwareType.T4}: {model_metadata['benchmark'][HardwareType.T4][-1]['batchInfTime']:.04f} ms")